На пути к «железным» СУБД
Нынешняя, третья волна аппаратной «акселерации» баз данных, хотя и несет с собой только одну принципиальную новинку — энергонезависимую память, но в сочетании с прогрессом в области сетей с RDMA, FPGA и графических ускорителей формирует широкий фронт. Главное отличие очередной волны — демократичность, позволяющая решиться на создание аппаратно-ускоренной СУБД не только крупным корпорациям и богатым калифорнийским стартапам, но и любым динамичным коллективам из разных стран, находящим свою нишу и предлагающим востребованный продукт. И эта тенденция — шанс как для отечественных разработчиков, так и для российских организаций — потребителей технологий баз данных.
Идея создания СУБД, использующих аппаратно-специфичные технологии, переживает очередную волну интереса, главное отличие которой — демократичность, позволяющая решиться на создание аппаратно-ускоренной СУБД не только крупным корпорациям и богатым калифорнийским стартапам, но и любым динамичным коллективам из разных стран, находящим свою нишу и предлагающим востребованный продукт.
Традиционные СУБД начала века на сколь-либо серьезных масштабах требовали и серьезного оборудования — многопроцессорных RISC-серверов и аппаратных систем хранения данных, что сильно сдерживало развитие цифрового бизнеса, которому было дешевле построить собственные СУБД с ограниченными возможностями, но способные горизонтально масштабироваться вместе с базами путем добавления недорогих стандартных узлов. Правда, мощность стандартного «строительного блока» — серверного узла x86-архитектуры, перешедшего в категорию товаров широкого потребления, — к концу 2010 года стала весьма значительной (десятки аппаратных ядер, терабайты оперативной и постоянной памяти на флеш-накопителях). В результате принадлежавшая France Telecom крупнейшая база данных 2002 года (32 Тбайт, 32 RISC-ядра) могла не только разместиться на одном таком блоке, но и параллельно обрабатываться.
Феномен больших данных во многом связан и с тем, что к концу 2000-х годов интересные, но не настолько ценные для организации данные, чтобы под них выделять дорогостоящее оборудование и ПО, стало возможным хранить и обрабатывать относительно дешево. По мере накопления опыта разработки и эксплуатации таких систем были выработаны стандартные подходы к их проектированию и эксплуатации, а также зафиксированы показатели и метрики оценки. И уже показалось, что индустрия вышла на плато простых и стабильных соотношений — стали понятны уровень параллелизма узлов, производительность и пределы масштабов кластеров. Но в середине 2010-х заметили, что производительность, достигаемая на больших кластерах под управлением вычислительных систем стандартной архитектуры, может на определенных нагрузках быть существенно повышена путем лишь небольших усовершенствований. Действительно, при наличии графического ускорителя один узел может выполнять уже не десятки, а тысячи потоков одновременно, а новые типы памяти позволяют целиком отказаться от типичного для дисков блочного ввода-вывода.
Освоение таких аппаратных добавок привело к появлению отдельного направления в СУБД-строении, важность и значимость которого подтверждаются глубоким интересом к нему одного из самых активных современных исследователей баз данных — Энди Павло из Университета Карнеги — Меллона, организовавшего семинар с участием ключевых разработчиков аппаратно-ускоренных СУБД. На сегодняшний день имеется четыре направления движения в сторону «железных» СУБД: графические ускорители, программируемые вентильные матрицы, суперкомпьютерные сети и энергонезависимая память.
Графические ускорители
Графические ускорители от ведущих игроков способны нести на борту тысячи вычислительных ядер и оснащены сверхбыстрой оперативной памятью GDDR, и задача разработчиков СУБД сводится «лишь» к распараллеливанию алгоритмов обработки данных и их доставке до GPU. Как следствие, все ускорившиеся таким способом СУБД ориентируются на аналитическую (читающую) нагрузку реального времени.
СУБД Kinetica работает в кластере без разделяемых ресурсов, используя формат хранения по столбцам и сегментирование данных между узлами. Эта СУБД развернута, например, в Почтовой службе США, где, по утверждениям разработчиков, 200 узлов поддерживают всю логистику обработки отправлений. Ускорение средствами CUDA позволяет хорошо распараллеливаемому коду обеспечивать за секунду обработку 150 млрд записей базы, что в 15 раз быстрее возможностей ведущей на рынке резидентной СУБД.
СУБД SqreamDB написана на функциональном языке Haskell, который, как и SQL, представляет собой сильно типизированный декларативный язык программирования. С некоторыми оговорками в нем может быть естественными средствами воспроизведен SQL как предметно-ориентированное подмножество. В отличие от Kinetica, здесь требуется общее хранилище: несколько экземпляров СУБД работают с единой базой данных, размещенной на внешнем ресурсе (аналогичная схема используется в Oracle Real Application Cluster). Такой подход ограничивает горизонтальную масштабируемость производительностью общей системы хранения, но позволяет работать с базой, размер которой превышает суммарную емкость оперативной памяти всех вычислительных узлов кластера. Кроме того, разработчики SqreamDB рекомендуют не бояться сложных SQL-соединений и предлагают не беспокоиться о подборе индексов — в SqreamDB они вообще отсутствуют. СУБД сама разбивает таблицы вертикально и горизонтально на относительно небольшие секции (один столбец — 1 млн записей по умолчанию) и для каждой секции хранит зонную карту. Атлас из этих карт фактически выполняет роль подсистем индексирования и статистики для планирования запросов (рис. 1). Утверждается, что один сервер с СУБД SqreamDB заменял пять и даже восемь телекоммуникационных шкафов, наполненных узлами массово-параллельных СУБД. Однако стоит настороженно относиться к таким «историям успеха», поскольку чаще всего подобные замены связаны с выводом из эксплуатации устаревшего оборудования, да и задачи со временем меняются.

Рис. 1. Схема работы SqreamDB: таблицы, разбитые на небольшие вертикально-горизонтальные секции, размещаются в общей системе хранения
На семинаре Павло были представлены и другие СУБД, ускоренные графическими адаптерами: MapD (недавно переименованная в OmniSci), Brytlyt и BlazingDB. Первая близка к Kinetica: работает с сегментированной по узлам столбцовой (поколоночной) базой, хранимой в основной памяти. Brytlyt построена на базе PostgreSQL, она наследует богатый вариант SQL, ускоряясь благодаря выгрузке на графический процессор операций фильтрации, сортировки, группировки и поддерживая непосредственное соединение на GPU. У СУБД BlazingDB, работающей напрямую с озерами данных со стандартными для них форматами Parquet и ORC, графическому ускорителю переданы операции по декомпрессии, при этом СУБД вообще не записывает данные, а лишь кеширует то, что ранее прочитала. Такое решение, фактически надстраивающееся над экосистемой Hadoop без какого-либо ETL, оказывается во многих случаях эффективным.
В каталоге партнерских решений компании Nvidia по состоянию на 2019 год перечислены десятки продуктов, которые так или иначе можно отнести к категории СУБД, использующих GPU для ускорения. Среди них есть и разработка российской компании «Полиматика» — BI-система с собственным столбцовым движком хранения (что сближает ее с Kinetica), выполняющая операции сортировки и кластеризации на видеокартах с поддержкой CUDA. Другой примечательный представитель каталога — ускоряющая добавка к графовой СУБД Blazegraph. Интерес к этой системе вызван не только тем, что само по себе применение GPU для графовых задач — редкость, но и тем, что большинство сотрудников компании-разработчика, включая ее генерального директора, перешли в Amazon, которая вскоре приобрела доменное имя blazegraph.com и выпустила облачную графовую СУБД Neptune.
Специфическая тенденция в развитии СУБД на графических ускорителях — поддержка архитектуры POWER, с которой работают Kinetica, SqreamDB, OmniSci и «Полиматика». Это можно объяснить наличием в процессоре Power9 шины NVLink, напрямую соединяющей графические ускорители на скорости до 200 Гбайт/с и позволяющей нескольким картам Nvidia «общаться» без пересылки данных в оперативную память общего назначения, что дает возможность фактически объединить несколько ускорителей в единое устройство, в рамках узла работающее с одним большим массивом данных.
Программируемые вентильные матрицы
Графический ускоритель работает только с системой команд конкретного GPU, а у программируемых логических интегральных схем (ПЛИС) (точнее, у наиболее развитого их подкласса — перепрограммируемых вентильных матриц FPGA (field-programmable gate array)) возможности гораздо шире. Идею использования FPGA для коммерческой СУБД в 2002 году реализовала компания Netezza, создавшая аппаратно-программный комплекс, фактически сформировавший рынок машин хранилищ данных (до этого представленный лишь одним производителем — Teradata). Система была построена на базе PostgreSQL, база данных сегментировалась по узлам без общих ресурсов, к каждому из узлов сегмента пристраивалась FPGA (такая пара называлась «сниппетом»). В Netezza матрицы FPGA применялись самым очевидным образом — для эффективного фактически аппаратного выполнения операций сжатия. Над упакованным сегментом базы данных матрица в Netezza умела выполнять проекцию и фильтрацию, а все прочие операции, включая агрегации и группировки, осуществлялись центральными процессорами. Если в большинстве массово-параллельных СУБД всегда ищется баланс между повышением фактической пропускной способности за счет сжатия и требуемыми для него дополнительными вычислительными ресурсами, то вынос «компрессионных» операций на устройство, которое делает это гораздо эффективнее, избавляет от поиска компромисса, направляя ресурсы процессоров общего назначения на работу с уже готовыми и предварительно отобранными массивами. К сожалению, IBM, которая приобрела Netezza в 2010 году, не выпускает машины баз данных с FPGA, а с середины 2019 года перестала их поддерживать. Главный «виновник» этого — прогресс, сделавший неэффективными комплексы, специально оптимизированные для использования небольших по емкости дисковых накопителей и малоядерных процессоров.
Каких-либо значительных результативных применений FPGA к базам данных с середины 2000-х до середины 2010-х годов отмечено не было, что связано со сложным циклом реализации готовых к тиражированию решений. Однако идея воплотить «в кремнии» операции работы с базами данных не покидала исследователей и производителей — публикации по этой теме собираются в увесистую подшивку. Некоторые из озвученных идей удалось буквально «воплотить в кремнии». Вслед за поглощением Sun Microsystems компанией Oracle в конце 2000-х годов в процессоры SPARC были «зашиты» аналитические и криптографические операции; тем самым внутри процессора общего назначения было реализовано то, что остальные игроки рынка вынуждены были бы делать на FPGA.
Во второй половине 2010-х годов был отмечен подъем интереса к FPGA, чему способствовала череда успешных применений этих устройств для работы с искусственными нейронными сетями. Подстегнутые успехом тензорного процессора Google, выполненного в формате специализированной микросхемы, за счет безрегистровых матричных вычислений и арифметики с пониженной точностью бьющего рекорды для нагрузок с использованием библиотеки TensorFlow, разработчики стали искать пути воплощения подобной схемы на доступном оборудовании, и тут оказалось, что альтернативы FPGA пока нет. Важным шагом к демократизации технологии стало появление виртуальных экземпляров FPGA в публичном облаке Amazon — любой подписчик AWS может арендовать «FPGA instance» с комплектом средств разработки.
Много усилий для продвижения технологии в широкие массы прилагают и основные производители FPGA — Xilinx и Intel, устройства которых все чаще можно встретить в составе готовых серверных платформ различных производителей, а последняя даже выпустила гибрид, объединяющий в одном корпусе процессор общего назначения Xeon и FPGA Aria 10.
Таким образом, само по себе применение FPGA в современных условиях уже не должно восприниматься как ограничение, привязка к конкретному поставщику или уход в класс экзотических решений. Теперь такие решения доступны и в составе серийного серверного оборудования массового класса, и в форме облачного ресурса.
Ставку на FPGA сделали, например, в проекте Swarm64, разработав ускоритель для PostgreSQL, MySQL и MariaDB, встраивающийся между подсистемой хранения и подсистемой обработки, силами FPGA «укладывающий» базу данных в сжатый столбцовый формат с эффективной декомпрессией данных.
Многообещающим внедрением FPGA в мир СУБД стала разработка Alibaba. Стремясь не отставать от Amazon Web Services, в октябре 2018 года Alibaba Cloud предоставила подписчикам возможность заказывать виртуальные машины, оснащенные FPGA, а уже месяц спустя сообщила о собственной СУБД X-DB, созданной на основе MySQL и использующей FPGA. Система дает эффект на транзакционных нагрузках: FPGA задействованы в упаковке журнально-структурированного дерева со слиянием, что освобождает центральный процессор и оставляет ему непосредственно транзакционную работу. Китайцы не выпускают систему за пределы своей организации и откровенно сообщают о том, что они находятся пока в «лабораторной фазе». На одном узле с FPGA они получают на TPC–C-подобном тесте около 15% прироста производительности по сравнению с обычной реализацией, а на OLTP-нагрузке в Sysbench — выигрыш около 40%, хотя и надеются на масштабных инсталляциях получить более значимый эффект.
Спектр возможных применений FPGA для СУБД достаточно широк, и здесь важны универсальные проекты, позволяющие интегрировать FPGA с СУБД, шаг за шагом воплощая в специализированной аппаратуре эффективные алгоритмы обработки данных.
В исследовательском проекте doppioDB, осуществляемом в Швейцарской высшей технической школе в Цюрихе, столбцовая резидентная СУБД MonetDB расширена аппаратными пользовательскими функциями (Hardware User-Defined Functions, HUDF), выполняемыми на FPGA. Это оказалось эффективно при реализации выборок по регулярным выражениям, запросов с оператором Skyline (выбор точек для задачи оптимизации) и операции стохастического градиентного спуска. Нет сомнений в том, что техника выноса специализированных функций для выполнения на специально предназначенном для них оборудовании будет открывать новые возможности по ускорению СУБД.
Суперкомпьютерная сеть
Стремление к применению на стороне сервера оборудования массового класса, кроме прочего, означает масштабируемость по горизонтали — фактически система управления базами данных становится вычислительным кластером, зависимым от производительности сетевого межсоединения. Особую остроту в этой связи приобретает переход к флеш-накопителям, задержка передачи данных по сети при работе с которыми превышает время чтения с SSD.
Публикуется много работ, посвященных организации работы СУБД в горизонтальном масштабе в условиях узкой, неотзывчивой и ненадежной сети. Однако в ИТ есть отрасль, в которой традиционно очень тщательно относились к межсоединениям, — суперкомпьютеры, работающие с такими сетями, как Myrinet, Infiniband, Omni-Path, сети с топологией многомерного тора. По состоянию на 2019 год более половины суперкомпьютеров из Top 500 использовали Infiniband. Эту технологию отличает не только высокая физическая пропускная способность (100 Гбит/с и выше), но и прямой доступ к памяти удаленных узлов (Remote Direct Memory Access, RDMA), выгрузка сетевых операций на адаптер для высвобождения центрального процессора и пр.
В мире машин баз данных сеть Infiniband применяется в комплексах Teradata и Exadata, и это их главная аппаратная отличительная особенность — все остальное «железо» с современной точки зрения вполне можно отнести к массовому классу. Высокая пропускная способность сетей Infiniband позволяет не столь радикально экономить на передаче данных между узлами, как это возможно для массово-параллельных СУБД, ориентированных на стандартную Ethernet-сеть. При этом и акт сетевого взаимодействия при использовании соответствующих лингвистических средств обходится для узлов значительно дешевле: если общение на языке сокетов требует копирования в память для каждого отправляемого и получаемого пакета, то при работе, например, с Verbs — «родным» языком Infiniband — взаимодействие происходит в парадигме нуль копирований (zero-copy) при прямом доступе к памяти удаленного узла.
Долгое время считалось, что суперкомпьютерные сети не предназначены для корпоративных применений: дорого в приобретении и обслуживании, отсутствует ПО, эффективно использующее сети типа Infiniband. Но ситуация меняется, и во многом благодаря распространению технологии RoCE (RDMA over Converged Ethernet), а также снижению стоимости адаптеров и коммутаторов — цена на порт для 100-гигабитной сети отличается от таковой в сети 10-Gigabit Ethernet уже не на порядок.
Интересен проект HyPer Технического университета Мюнхена, в котором с немецкой аккуратностью точно измерена производительность и на TPC-H-подобном тесте для всех заложенных в спецификацию запросов показано явное преимущество RDMA. Имеется большой пласт исследовательских работ, посвященных анализу эффекта от RDMA в транзакционной среде. В частности, группа авторов во главе со Стоунбрейкером рассчитывает на то, что применение RDMA в реализации распределенных транзакций позволит резко снизить накладные расходы и наконец-то продвинуться в решении задачи распараллеливания транзакционной нагрузки в общем виде.
Однако, несмотря на впечатляющие возможности RDMA и наличие множества исследований и прототипов, в мире СУБД за пределами решений крупных корпораций (кроме Oracle и Teradata, поддержка RDMA реализована в IBM DB2 PureScale и корейской системе Tmax Tibero) применений этой технологии мало. В начале 2010-х годов стартап Clustrix выпустил на рынок кластерный вариант MySQL, упакованный в x86-узлы, соединенные по Infiniband, но с 2014 года комплексы не продаются, и остатки активов Clustrix выкуплены MariaDB и превращены в столбцовый движок их СУБД, а от сетевого решения ничего не осталось.
Тем не менее определенные подвижки имеются, причем в России. В аппаратно-программном комплексе на отечественном оборудовании Скала-СР / Postgres Pro применено 100-гигабитное RoCE-межсоединение, а для доставки журналов упреждающей записи между узлами кластера задействована RDMA благодаря специально написанному дополнению. Это дает практически неограниченную масштабируемость по синхронному чтению: можно добавлять 5, 10, 15 узлов для синхронных реплик (рис. 2), поскольку доставкой журналов занимается не центральный процессор ведущего узла, а сетевое оборудование.

Рис. 2. Показатели производительности Скала-СР / Postgres Pro в конфигурации с RDMA и без нее
Другая российская разработка в этом направлении — графовая СУБД с поддержкой SQL NitrosBase, ранее известная как RDF-система. Сегодня это распределенная графовая СУБД, написанная на языке C++, что само по себе достаточно специфично. (Американский стартап TigerGraph вышел на рынок с похожими идеями в конце 2018 года.) Важнейшая отличительная особенность NitrosBase — работа с RDMA на языке Verbs, благодаря чему система эффективно решает задачу обработки распределенного графа, десятилетиями считавшуюся неразрешимой. Теперь СУБД может обратиться к вершинам соседнего узла практически с той же скоростью, что и к локальным, — это позволяет произвольным образом сегментировать базу данных, не заботясь о месте выполнения, которое невозможно предсказать на произвольных графовых запросах.
Суперкомпьютерные сети становятся все более доступными для корпоративных ЦОД, и здесь стоит обратить внимание на дальнейшую «коммодитизацию»: ряд возможностей, ранее доступных только в специализированных сетях, реализуются программно на уровне сетевого стека. По такому пути пошла СУБД ScyllaDB — копия Apache Cassandra, в которой применяется C++ вместо Java, что позволило получить существенный прирост производительности. Разработчики реализовали собственный альтернативный сетевой стек с использованием набора библиотек DPDK (Data Plane Development Kit), позволяющего исключить сетевой стек ОС из процесса обработки пакетов и предоставить приложению возможность работать напрямую с сетевыми устройствами, оставаясь в пространстве пользователя в рамках сетевых взаимодействий вне зависимости от свойств сетевого оборудования. Тем не менее до суперкомпьютерных возможностей в сетях общего назначения, построенных на произвольном оборудовании, еще далеко, а сложность программирования весьма высока.
Энергонезависимая память
Возможно, самая революционная аппаратная новинка, сулящая изменения для мира СУБД, — энергонезависимая байтоадресуемая память. Все системное и платформенное ПО, написанное в эпоху господства архитектуры фон Неймана, пропитано концептуальным различием между оперативной памятью, теряющей данные при сбое или перезагрузке, и медленным блочным устройством, позволяющим данные сохранить. Появление быстрых SSD лишь немного сократило пропасть между этими двумя классами устройств в вопросе скорости доступа, но не в принципах работы с данными.
Энергонезависимая память меняет картину кардинально — теперь хранимыми данными можно манипулировать прямо из процессорных команд, нет нужды формировать блоки данных и через интерфейсы очередей «поднимать» их в память и «сбрасывать» на накопитель при изменениях. Естественно, все это требует иной модели программирования, других библиотек. К концу 2010-х годов в рамках инициативы PMDK (persistent memory development toolkit) такая модель была создана.
Существует несколько типов материалов, позволяющих реализовать энергонезависимые модули байтоадресуемой памяти. Примечательна разработка магниторезистивной памяти с переносом спинового момента (STT MRAM) со сверхнизкой энергией доступа, ведущаяся российско-французским предприятием «Крокус-наноэлектроника»; есть и паллиативное решение NVDIMM-N – обычная DRAM с флеш-защитой (микроконтроллер, питающийся от автономного элемента, получив сигнал о сбое, скопирует все содержимое памяти на флеш-накопитель и восстановит при следующей загрузке). Однако, несмотря на прогресс в создании таких устройств, применимость большинства из них для корпоративных баз данных ограничена: либо высока цена, либо размер одного модуля чрезвычайно мал. Но есть и исключение: альянсом Intel и Micron был создан фазопереходный материал 3D XPoint, модули на основе которого достаточно емки и стоимость единицы хранения в которых не выше, чем на обычных «планках» оперативной памяти (рис. 3).
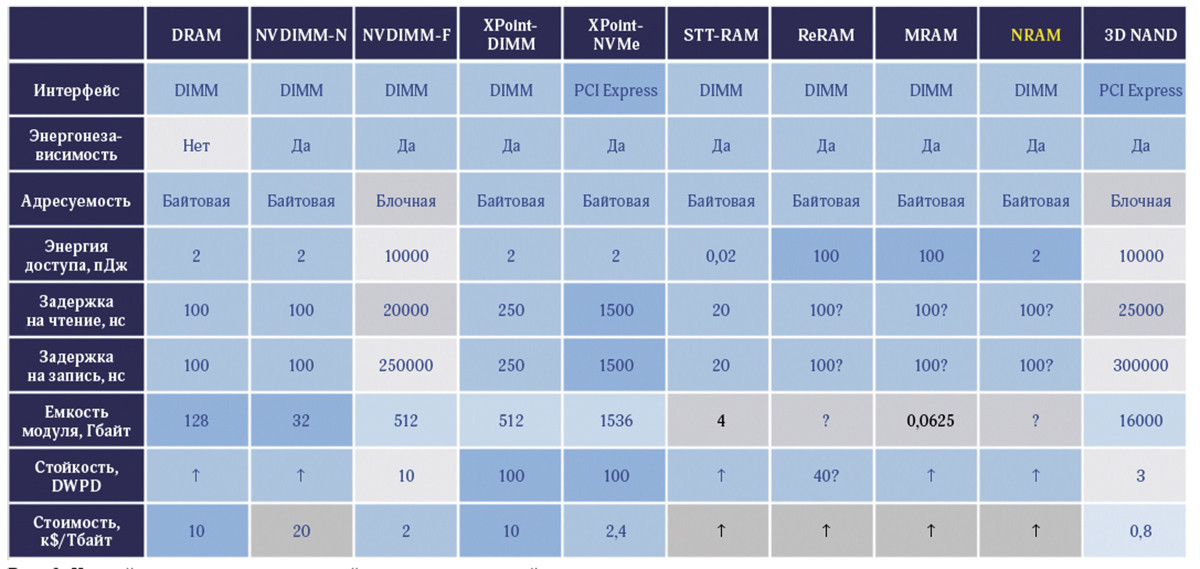
Рис. 3. Устройства энергонезависимой и энергозависимой памяти
Примечательно, что первыми у альянса были выпущены устройства с разъемами PCI Express, а не с традиционными DDR. На практике их чаще всего применяют как обычные SSD (лишь со сверхвысокими показателями по перезаписываемости). В принципе, их также можно использовать и в байтоадресуемом режиме: интерфейс MMIO (Memory Mapped Input-Output) позволяет общаться с таким PCIe-устройством через инструкции load/store. Есть также программная возможность представить такое устройство как виртуальный беспроцессорный NUMA-узел и включить его в пул оперативной памяти машины, в этом случае, правда, энергонезависимость не используется. Одна из реализующих эту возможность программных прослоек — израильская ScaleMP, предлагаемая также Intel под собственной маркой Memory-Drive Toolkit (IMDT) вместе с устройствами Optane, — демонстрирует достаточно хорошие показатели: резидентная российская СУБД Arenadata Grid на базе Apache Ignite показывает лишь двойную деградацию производительности на тесте Yardstick на таким способом «растянутой» оперативной памяти по сравнению с памятью «настоящей». Это достаточно хороший результат — сегодня доступны полуторатерабайтные устройства Intel Optane для PCI Express, позволяющие на одном двухпроцессорном узле агрегировать более десятка терабайт для резидентной базы. Таким образом, для стотерабайтного кластера с поддержкой таких устройств потребуется впятеро (или даже на порядок) меньше узлов.
Однако полностью воспользоваться возможностями энергонезависимой памяти можно только при значительных переделках СУБД. Практических реализаций пока немного, хотя к появлению энергонезависимой памяти готовились давно. Есть ряд исследований по переобустройству СУБД: не хранить журнал упреждающей записи либо формировать транзакционный журнал после записи; изменить структуры для репликации; применить техники антикеширования и избавиться от буферов в оперативной памяти; модифицировать структуры индексов. С недавнего времени в SAP HANA поддерживается размещение столбцовой части базы данных в энергонезависимой памяти — при перезагрузке этот сегмент не нужно «поднимать» с накопителя. Поддержка энергонезависимой памяти обещается в Aerospike, Redis и Gigaspaces, а в феврале 2019 года группа корейских исследователей на ежегодной конференции USENIX по технологиям хранения обнародовала проект NoSQL-системы класса «ключ-значение», изначально работающей с энергонезависимой памятью и объединяющей свойства индексов на основе B+-деревьев и журнально-структурированных деревьев со слиянием. Кроме этого, имеются клоны Redis, RocksDB и MongoDB с расширениями под энергонезависимую память, а в марте 2019 года группа исследователей Калифорнийского университета в Сан-Диего сообщила о первых результатах эталонных тестов этих систем.
Переходит на энергонезависимую память и СУБД NitrosBase; первые эксперименты показали, что вынос транзакционного журнала с блочного NVMe SSD (Non-Volatile Memory Express) на энергонезависимую память, установленную в разъемы DDR, дает 15-кратный прирост производительности на записи 100 млн записей по 20 байт. Произвольный доступ к данным, размещенным в байтоадресуемой памяти (1 млн записей из базы объемом 500 Гбайт) дает прирост более чем в 20 раз по сравнению с доступом к быстрому блочному устройству, хотя на многопоточном доступе выигрыш не столь значимый (на 8 потоках — чуть более чем в семь раз), что указывает направление дальнейших работ по совершенствованию нового движка NitrosBase для энергонезависимой памяти.
***
Воплощение в жизнь идеи «железных» СУБД, использующих аппаратно-специфичные технологии, переживает естественные циклы. Первая волна носила исследовательско-теоретический характер и по мере накопления идей сменилась восторгом, выразившимся в заглавии статьи Дэвида Сяо 1979 года: «Database Machines are Coming, Database Machines are Coming!». Но была разбита категоричным выводом: «прогресс дисковых массивов и подсистем ввода-вывода мини-компьютеров сделал разработку машины баз данных экономически нецелесообразной» [6]. Тем не менее компании Britton-Lee, Teradata, а затем и Netezza построили коммерчески успешные серийные машины баз данных. Апофеозом второй волны стала система Oracle Exadata, связавшая суперкомпьютерной сетью экземпляры баз данных и «думающие» ячейки хранения. Она же внесла вклад в переключение внимания исследовательской общественности на более простые и недорогие решения.
Нынешняя, третья волна аппаратной «акселерации» баз данных, хотя и несет с собой только одну принципиальную новинку — энергонезависимую память, но вкупе с прогрессом в области сетей с RDMA, FPGA и графических ускорителей формирует широкий фронт. Главное отличие очередной волны — демократичность, позволяющая решиться на создание аппаратно-ускоренной СУБД не только крупным корпорациям и богатым калифорнийским стартапам, но и любым динамичным коллективам из разных стран, находящим свою нишу и предлагающим востребованный продукт. И эта тенденция — шанс как для отечественных разработчиков, так и для российских организаций — потребителей технологий баз данных.
Литература
1. A. Pavlo. Hardware Accelerated Database Lectures // CMU, Fall 2018. URL: https://db.cs.cmu.edu/seminar2018/ (дата обращения: 10.03.2019).
2. Андрей Николаенко. Машины баз данных: концентрированное обозрение // CXCVII семинар Московской секции ACM SIGMOD, 2017. (дата обращения: 10.03.2019).
3. Р. Хардинг, Д. ван Акен, Э. Павло, М. Стоунбрейкер. Оценка протоколов управления распределенными транзакциями // CitForum, перевод с английского – С.Д. Кузнецов. URL: http://citforum.ru/database/articles/transaction_evaluation(дата обращения: 10.05. 2019).
4. Владислав Головков, Андрей Портнов, Виктор Чернов. RDF – инструмент для неструктурированных данных // Открытые системы.СУБД.– 2012.– № 9. – С. 46–49. URL: https://www.osp.ru/os/2012/09/13032513/ (дата обращения: 29.05.2019).
5. Arulraj, A. Pavlo. Non-Volatile Memory Database Management Systems. – Morgan & Claypool, 2019.– 173 p. ISBN: 9781681734842.
6. H. Boral, D. DeWitt. Database machines: an idea whose time has passed? A critique of the future of database machines // In: Parallel architectures for database systems, A. R. Hurson, L. L. Miller, and S. H. Pakzad (Eds.). Piscataway, NJ: IEEE Press. – P. 11–28.
Дмитрий Волков (vlk@keldysh.ru) – сотрудник ИПМ им. М. В. Келдыша РАН, Андрей Николаенко (ANikolaenko@Ibs.ru) – архитектор, компания IBS (Москва).